After the 2016 political election I ended up being a lot more interested in media bias as well as the adjustment of individuals with advertising. Hence, it uses an outstanding opportunity for you to use only one language to recognize the internal workings of a website and also scrape information from it. This will make your code cleaner and reduce the knowing procedure in the future. JavaScript and Python are 2 of one of the most preferred and flexible shows languages. Both languages go to the forefront of development in web scuffing, boasting a huge choice of structures and also libraries that supply devices to get over also one of the most intricate scraping situations.
- Big improvements in information scuffing from pictures as well as video clips will certainly have significant effects for digital marketing experts.
- The entire factor of a crawler is to spot and also go across web links to other web pages and grab data from those web pages too.
- There is an open Scrapy Github problem that reveals that external Links do not get removed when OffsiteMiddleware is applied prior to RedirectMiddleware.
- They made use of a data collector to get internet information required to gain insights into clients and also fads and also focus on analytical options for their consumers.
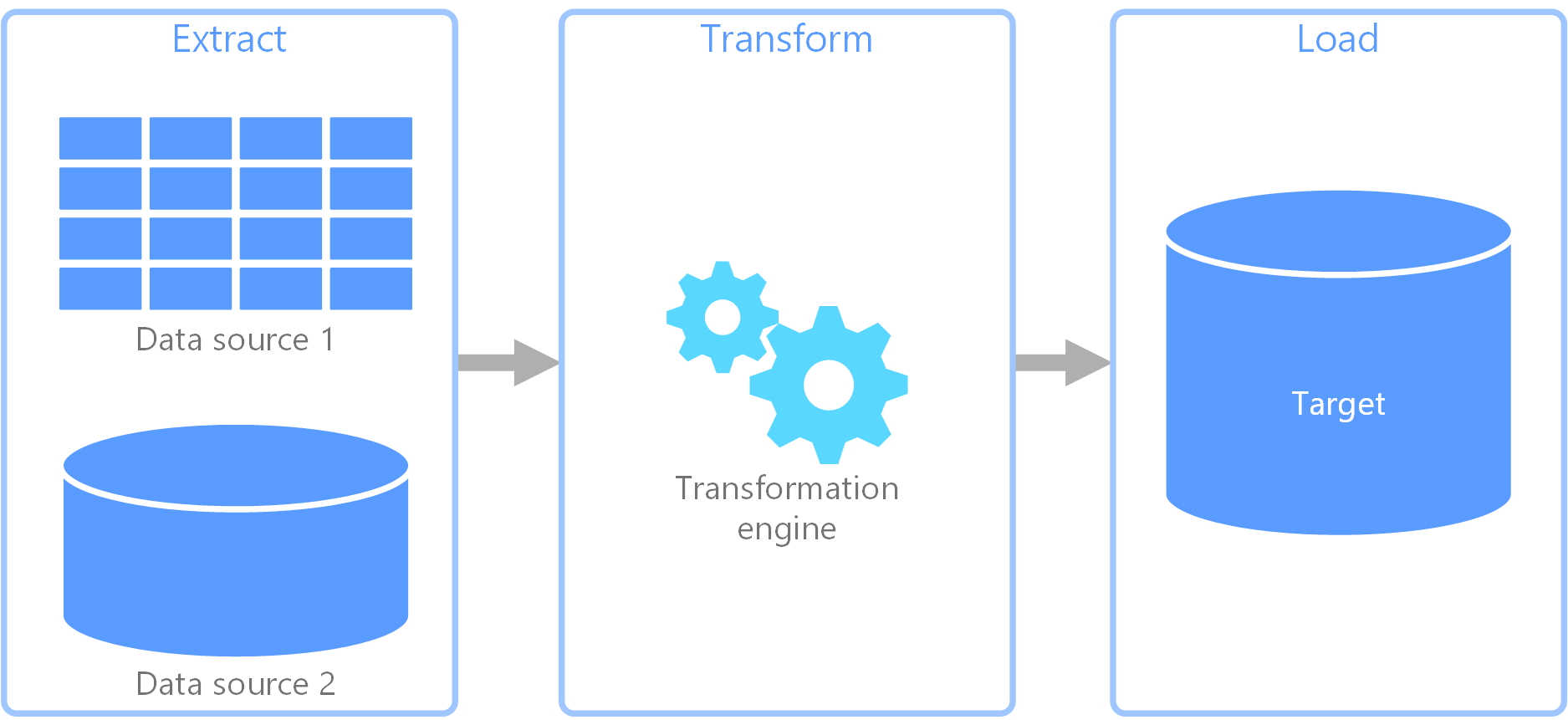
- Once we have the HTML we can after that parse it for the information we want examining.
This command develops a new job with the default Scrapy job folder structure. To run our crawler, simply enter this command on your command line. A basic spider can be constructed adhering to the previous design layout.
What Is Data Scuffing?
The Crawler course has approaches and behaviors that specify exactly how to adhere to Links and essence information from the web pages it finds, however it doesn't know where to look or what information to search for. The scraper will certainly be easily expanding so you can dabble about with it and also utilize it as a structure for your own tasks scraping information from the internet. We have the tools to make some relatively complex internet scrapers currently, yet there's still the problem with Javascript rendering. This is something that deserves its own write-up, but for currently we can do fairly a lot.
What is the distinction in between junking and creeping?
Web scuffing goals to extract the information on websites, and internet creeping purposes to index and locate website. Internet crawling entails complying with links completely based on hyperlinks. In contrast, internet scratching implies composing a program computer that can stealthily accumulate data from numerous websites.
As they're not aware of the difference, they usually pull out replicate details from an article that may have been plagiarised from a different resource. Furthermore, crawlers help in inspecting web links and verifying HTML codes. Web spiders likewise have other names such as automated indexers and also robotics. On the various other hand, web scuffing downloads web pages to remove a certain collection of information for analysis purposes, for example, item information, pricing information, search engine optimization information, or any type of other data collections. However an additional creeping instance would be when you have one website that you intend to extract data from - in this instance you know the domain - but you don't have the page URLs of that details internet site.
Current Write-ups:
" Crawling permits us to take unstructured, scattered information from multiple sources and collect it in one area and also make it structured," claims Marcin. " If you have several web sites managed by various entities, you can incorporate it all right into one feed. Information scraping as well as data creeping are related strategies to make it confusing for you. But after reading this post, we wish you'll be clear concerning the context, the points of distinction, and making use of both. Data scratching solutions can execute tasks that are unable to be completed by software crawling devices, such as performing javascript, sending information layouts, defying robotics, and so on.
As a result of that, both collections have lots of resemblances, lowering the finding out contour and also lowering the problem of migrating from one collection to an additional. Internet browsers are a method for individuals to gain access to and also engage with the info available online. Nonetheless, a human is not constantly a demand for this interaction to take place. Browser automation tools can resemble human actions as well as automate a web browser to do recurring and also error-prone jobs. The goal of the project is to make HTTP requests simpler and a lot more human-friendly, therefore the title "Requests, HTTP for people." Got Scraping is a contemporary plan extension of the Got HTTP client.
You can develop this data using the modifying software program of your option. It appears as None due to the fact that this aspect is provided with Javascript and also requests can not pull HTML made with Javascript. We'll be looking at just how to obtain information rendered with JS in a later short article, but given that this is the only piece of details that's made this way we can manually recreate the text. With Python's demands collection we're obtaining a websites by using get() on the link.
Just keep in mind that in the majority of these instances, it will suggest web scraping/crawling instead of information scraping/crawling, disregarding to their precise definitions. The brief version is that web scuffing is about extracting the Web Scraping Services information from one or more web sites. Data scraping is less complicated to configure, as Custom web scraping services it can be customized to complete any kind of particular job as well as get over any kind of possible obstacles that may happen while doing so.
Develop A Å Totally Free Personalised ¥ Learning Strategy To See Our Training Course Suggestions Î For You
Specific internet sites reject to provide any kind of public APIs because of technological limitations or various other factors. In such situations, some individuals might choose RSS feeds, but I don't suggest utilizing them due to the fact that they have a number limitation. What I wish to talk about here is just how to construct a crawler on our own to handle this situation.
https://maps.google.com/maps?saddr=130%20King%20St%20W%20%231800%2C%20Toronto%2C%20ON%20M5X%201E3%2C%20Canada&daddr=2%20Bloor%20St%20W%2C%20Toronto%2C%20ON%20M4W%203E2%2C%20Canada&t=&z=15&ie=UTF8&iwloc=&output=embed
You don't require any kind of technological knowledge to execute intricate web scuffing tasks. To place it merely, HTML parsing is generally absorbing HTML code and also drawing out relevant information like the title of the page, paragraphs in the web page, headings in the web page, web links, vibrant text, etc. It's primarily an internet crawler that methodically browses the World Wide Web, usually for the function of web indexing. You can have web scrapers that are self-built, yet that requires advanced programming knowledge. And also in your web Scrape, if you want extra functionality, then you need even more expertise. On the various other hand, scrapes that can easily be downloaded and install as well as run are formerly created pre-built internet scrapers yet with some constraints.
Drone Service market is projected to grow at a CAGR of 19.8% by ... - GlobeNewswire

Drone Service market is projected to grow at a CAGR of 19.8% by ....
Posted: Wed, 12 Jul 2023 12:00:00 GMT [source]
What is the difference between ditching as well as creeping?
Web scratching aims to draw out the data on web pages, as well as web creeping purposes to index and locate web pages. Web crawling includes following links completely based upon hyperlinks. In contrast, internet scraping suggests creating a program computing that can stealthily collect data from numerous web sites.